학부 수업 자연어처리및실습에서 국립국어원의 과제를 골라 수행하고 리더보드 순위대로 점수를 주는 텀 프로젝트를 진행했다.
여러 과제에 참가했고, 그 중 모델을 파인 튜닝하고 학습시키는 과정이 기억에 남을 경험이어서 기록으로 남겨본다.
과제 개요
내가 수행한 과제는 부적절성 문장에 대한 태도 탐지이다.
과제의 목표는 주어진 문장 내에 부적절한 표현이 있다면 해당 표현이 문맥상 긍정적인지 부정적인지 판단하는 것이다.
예를 들어, 아래 문장은 긍정적일까 부정적일까?
생일 축하해 시발럼
욕설을 사용하였지만 과하게 축하하는 의미로 긍정적이라고 할 수 있다. 실제로 주어진 훈련 데이터셋에서 위 문장의 레이블은 POSITIVE이다.
이렇게 욕설이나 부정적인 표현이 문장 내에 포함되어 있더라도 문맥적으로 긍정적일 수 있기에 이러한 표현을 잘 잡아내어 문장의 긍정/부정을 판단하는게 중요하다.
사용한 모델
내가 사용한 모델은 서울대학교 자연어처리 연구실에서 배포한 KR-ELECTRA 모델이다.
해당 모델 repository를 보면 파인튜닝 하는 코드를 제공한다.
서울대 자연어처리 연구 팀 측에서, KR-ELECTRA에 네이버 영화 리뷰 데이터(NSMC)와 하이퍼파라미터 튜닝으로 뛰어난 성능을 보이는 것을 확인했다고 한다.
어떻게 하이퍼파라미터를 지정하였는지 확인하고자 config 파일을 뜯어보았다.
config 파일을 보면 weight_decay가 디폴트 값인 0이다. weight_decay를 따로 설정하지 않고 파인 튜닝을 진행한 점이 신기했다.
학부 딥러닝 수업에서 weight_decay를 적절하게 지정하여 오버피팅을 방지함으로써 모델 성능 향상을 이끌 수 있다고 배웠었다. 실제로 이번 부적절성 문장 태도 탐지 과제에서 weight_decay를 디폴트 값이 아닌, 0.01로 지정하여 훈련했었다.
그런데 서울대 연구팀에서는 weight_decay를 0으로 지정하고 파인 튜닝하였다. 이게 결과적으로 가장 좋은 성능을 이끌어 냈기에 했을텐데, 디폴트 값을 사용해도 모델이 오버피팅 되지 않고 가중치 업데이트 과정이 안정적이었기에 그러지 않았나 싶다.

아무튼 해당 파라미터 세팅으로 아래와 같이 뛰어난 결과를 보임을 확인하였다고 한다.

아쉽게도 파인 튜닝한 모델을 공개하고 있지는 않아서, 해당 repo 리드미를 따라 파인 튜닝을 진행하였다.
다행히 문제 없이 잘 진행되는 모습이다.

지도교수님께서 제공해주시는 GPU 서버의 RTX 3090을 사용하는데도 5시간에 가까운 시간이 소요됐다.
내 맥북에서 돌렸으면 아마 3일이 넘게 걸렸을 수도.. 역시 컴퓨팅 자원 좋은게 매우 매우 중요한 것을 다시금 느낀다.
아무튼.. 아래와 같이 토크나이저를 로드한다.
from transformers import AutoTokenizer
model_id = "snunlp/KR-ELECTRA-discriminator" # fine-tuned ELECTRA model for NSMC
tokenizer = AutoTokenizer.from_pretrained(model_id)
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_train_dataset = train_dataset.map(tokenize_function, batched=True)
tokenized_test_dataset = test_dataset.map(tokenize_function, batched=True)
파인튜닝한 모델의 체크포인트도 로드해준다.
from transformers import BertForSequenceClassification, Trainer, TrainingArguments, AutoModelForSequenceClassification
import torch
model_checkpoint = "./ckpt/krelectra-nsmc-ckpt/checkpoint-2000/"
model = AutoModelForSequenceClassification.from_pretrained(model_checkpoint, num_labels=2)
평가 매트릭 함수는 아래와 같다.
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
# Calculate accuracy
accuracy = accuracy_score(labels, preds)
# Calculate precision, recall, and F1-score
precision = precision_score(labels, preds, average='weighted')
recall = recall_score(labels, preds, average='weighted')
f1 = f1_score(labels, preds, average='weighted')
return {
'accuracy': accuracy,
'precision': precision,
'recall': recall,
'f1': f1
}
훈련 인자와 trainer를 선언해주고 훈련을 해보자.
from transformers import TrainingArguments, Trainer, EarlyStoppingCallback
training_args = TrainingArguments(output_dir="test_trainer",
evaluation_strategy="epoch",
save_strategy="epoch",
num_train_epochs=10,
load_best_model_at_end = True,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_train_dataset,
eval_dataset=tokenized_test_dataset,
compute_metrics=compute_metrics,
callbacks=[EarlyStoppingCallback(early_stopping_patience=3)]
)
trainer.train()
아래와 같이 10 epoch 중 5 epoch 진행되었다. EarlyStopping을 지정해놓아서 더 이상 정확도가 올라가지 않자 훈련이 종료된 모습이다.

평가 결과는 아래와 같다.
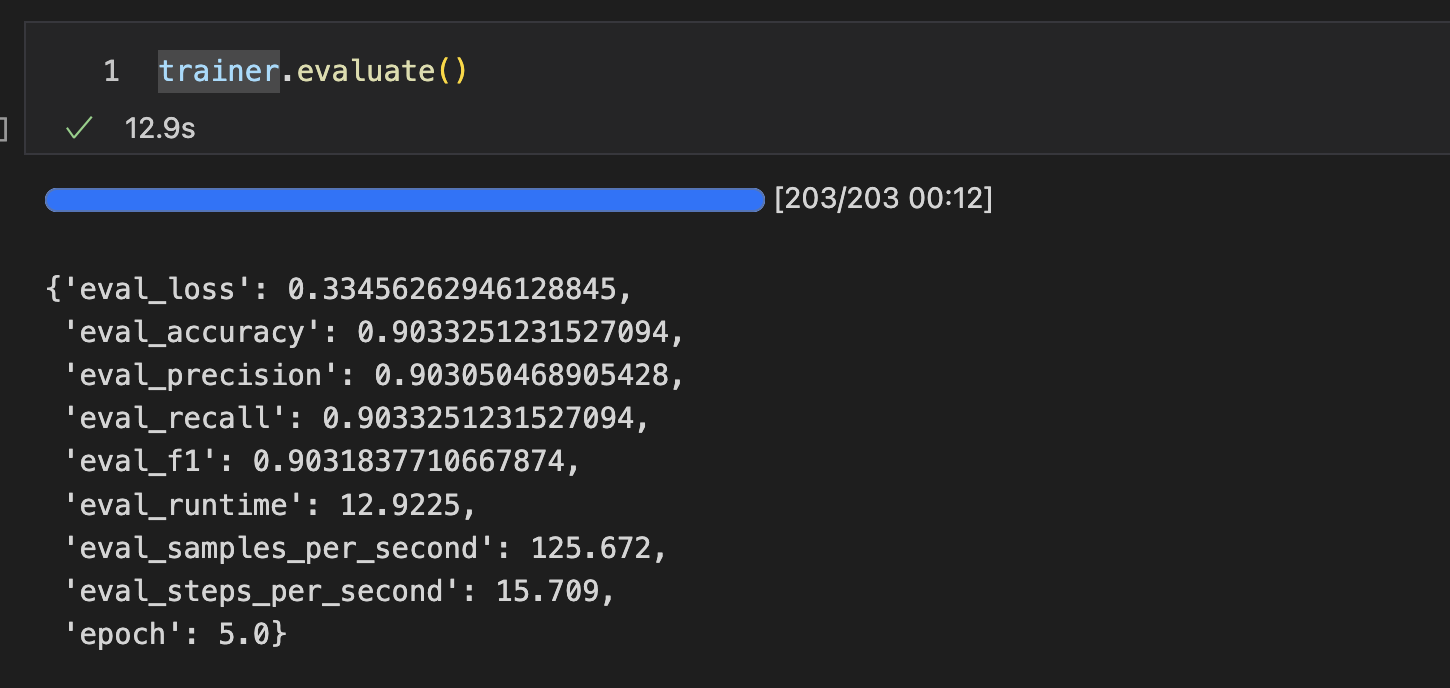
이제 태도 탐지 과제에서 주어지는 테스트 데이터셋에 대해 예측해보자.
테스트 데이터셋은 아래와 같은 양식이다.
학습시킨 모델로 output을 예측하여 채워 넣고 국립국어원 말평 홈페이지에 평과 결과를 제출하면 된다.
{"id": "nikluge-2023-iau-test-000001", "input": "아니 진짜 미친놈아니에요?????", "output": ""}
{"id": "nikluge-2023-iau-test-000002", "input": "아진심 미쳘냐공ㄱ", "output": ""}
{"id": "nikluge-2023-iau-test-000003", "input": "먹고후회할바엔 먹지말자 ㅅㅂ", "output": ""}
{"id": "nikluge-2023-iau-test-000004", "input": "심멎사진 나갑니다", "output": ""}

평가 결과는 아래와 같다.
파인튜닝한 모델은 87%의 정확도를 보였다.

말평에는 태도 탐지 과제 외에도 재미있는 과제가 많으니 도전하면 재미있을 듯 하다.
전체 코드는 저장소에서 확인할 수 있다.